Cloudflare Workers or Edge computing is a very neat way of serving tailored contents to the end-user. The basic idea of edge computing is to compute, alter or render an HTTP request at the CDN level - 200 different datacenters spread around the world vs a few locations on remote datacenter (if you are lucky to build such platform).
So anywhere the client is, it will always be served at close as possible from an edge server with low latency.
Please note, this article is not about Worker Site.
Where does the Cloudflare Workers work?
On the edge, but not after the CDN, actually, the Worker environment has nothing to do with the CDN environment, don’t expect to use any features from Cloudflare CDN in a Worker. The Worker is a standalone execution unit from the CDN. What is the impact? Well, don’t expect to cache the response from the worker using the CDN infrastructure.
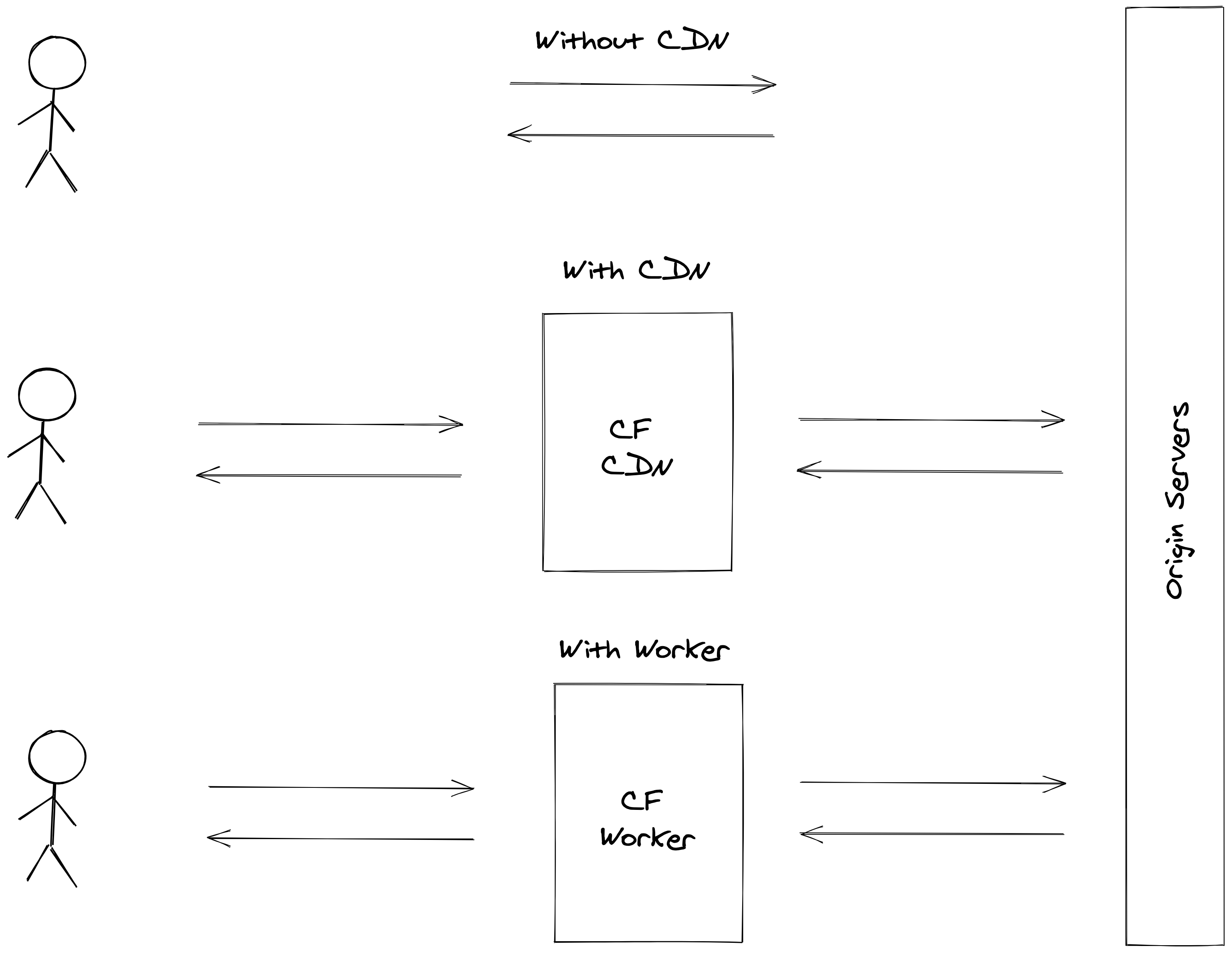
How does Cloudflare Workers work?
The engine is built on top of the V8 engine to match Cloudflare’s internal requirements. The final result is an engine working as a WebWorker with a limited set of JavaScript + some add-ons like a KV engine or non-standard Fetch API options.
The thing that needs to be understood, is that NodeJS libraries cannot be used, as only “browser” libraries work. There is another catch, the only way to make a remote HTTP request is by using the Fetch API. So if the selected library or the third party SDK does not rely on the Fetch API, well … there is no other option to recode or to find an entry point in the library to change the HTTP request handler.
The worker has also an important limitation, CPU time, not execution time, but CPU time. So the worker can be very efficient at aggregating data from different sources as long as there is no important computation to perform.
Please note: if the worker consumes too much CPU, ie: CPU time > 50ms then you are out of luck. The worker will be killed, with no options. Cloudflare does not provide a way to consume 2 CPU units if the worker spends 80ms of CPU time. So be careful of the kind of processing you are planning to do on the edge.
The working model is similar to any web framework, the handler gets a request, and the handler must return a response. Cloudflare did a very good job by respecting the WebWorker API. Any subrequest (fetch or kv calls) inside a worker return a stream resource that can be used directly inside the Response object.
This makes the overall experience very good.
How to develop a worker?
There are 2 main options:
- The integrated UI allows to test, run and deploy code in a few seconds.
- The local wrangler dev environment allows to use of libraries and build a final package with webpack.
Debugging is limited by running console.log in the dev environment and that it … there is no out-of-the-box way to get the log from a worker. The only way to get the log, it is to subscribe to the Argo service and use the wrangler command.
The wrangler local env is not yet stable, some rust error can show up here and here. But it is “working”.
Once a worker is deployed, it can be assigned to multiple routes and domains available in the user account. This is a good solution if you have many different domains with the same purposes.
What to do with a worker?
Good question, many things can be done! Some obvious examples are:
- Build a paywall based on some cookie values
- Control access
- Rewrite URL
- Alter response depends on specifics rules
- Send analytics/metrics
Seems, others have managed to develop more advanced solutions: https://blog.cloudflare.com/rendering-react-on-the-edge-with-flareact-and-cloudflare-workers/. Let’s focus on the obvious examples, as I do think, they represent 99% of use cases for Worker right now. For other types of workflow, I will put them on the side until Worker Unbound is unleashed.
So, let go back to the obvious examples, they are all going to get the request, apply some logic, call some endpoints, apply some logic and return the response to the client. This can be viewed as a Reverse Proxy with enhanced capabilities.
With that in mind, it is now really easy to see the scope of what a worker can do and should do.
How to integrate a worker in your infrastructure?
They are two options:
- Use the internal worker URL, like https://http.rabaix.workers.dev/ : just find a nice name, and you are good to go. There is no benefit of using the internal name, but the option exists.
- Route the traffic to your worker in the Workers section, ie:
http.rabaix.net/*to HTTP worker - Please make sure to not forget the*at the end to catch all URLs! Otherwise, you might lose some debugging hours … The last step is to configure the DNS to point to any private IP, ie:192.0.2.1. This will tell Cloudflare to look for a worker in the current zone.
Let’s say the worker need to deal with all HTML responses. Then the route needs to be www.thedomain.com/* , however, there is no way in the routing configuration to discard assets: JPG, PNG, CSS, JS, …. so the worker will be invoked for those URLs too. The only viable solution is to server those files under a different sub-domain. These will help to avoid consuming the worker credit too quickly.
The worker output cannot be cached. However, the worker can still call a subdomain with a caching rule in place, so the response will be cached at Cloudflare level and most of the Cloudflare features can be used, and with the worker in front of the cached domain, it is now possible to modify the output ….. but also control what is hitting the cache.
Example 1: Workers as request rewriter
This example will use a worker to clean a request before being passed to Cloudflare CDN.
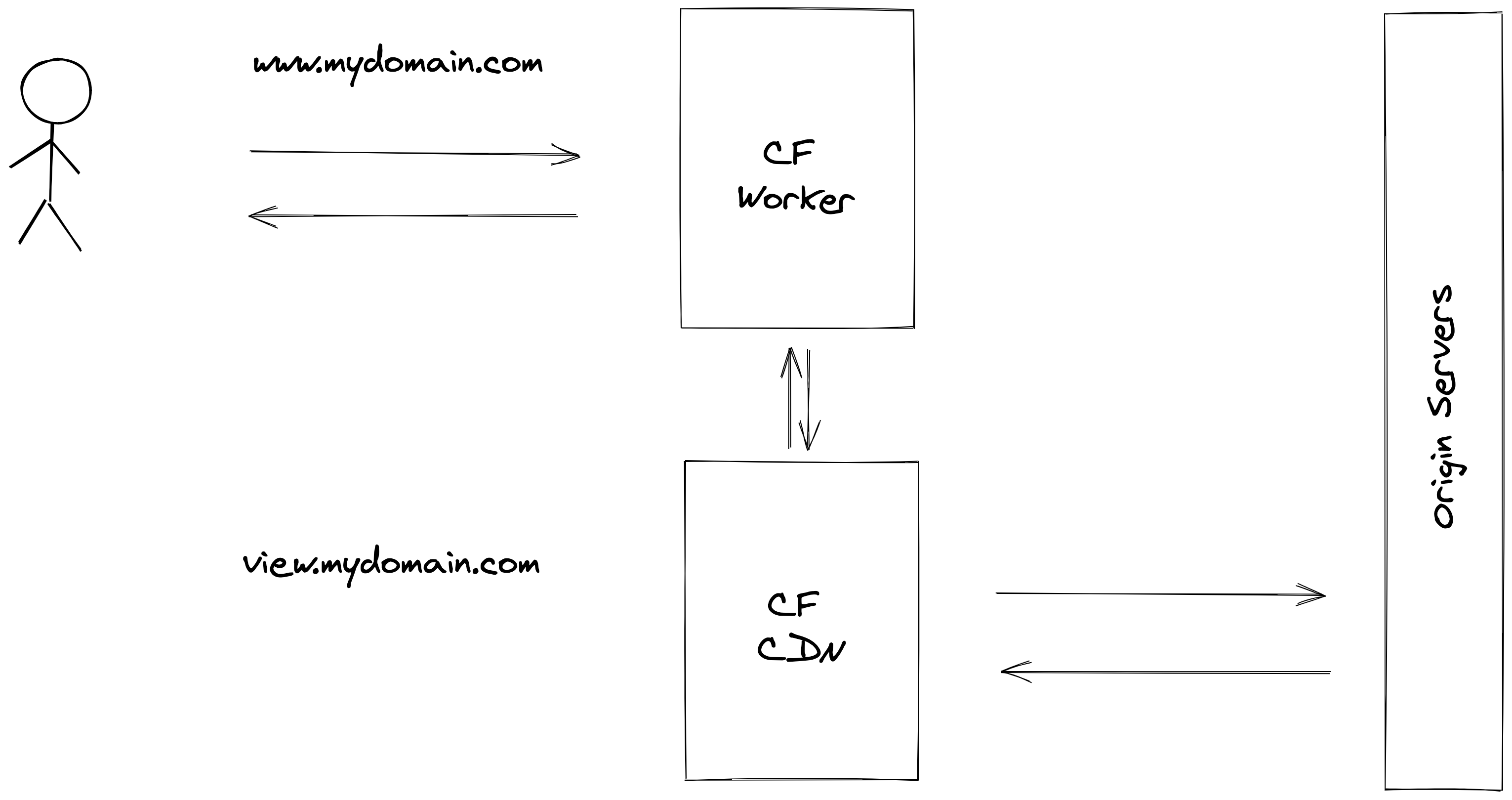
So, let’s say the client is sending the request:
GET HTTP/1.1 /articles?utm_arg=toto&page=2
cache-control: max-age=0
cookie: foo=bar
Host: www.mydomain.com
The worker gets the request and will forward it to an internal domain view.mydomain.com managed by Cloudflare CDN. Before forwarding any request, the worker will rework a bit the request to:
GET HTTP/1.1 /articles?page=2
Host: view.mydomain.com
X-Forwarded-Host: www.mydomain.com
Spot the difference?
- Tracking data “utm_args” has been removed, there is no usage for the backend. Most of the time, this is used by the frontend libraries.
- Cache-Control has been removed, so now the client cannot force the backend to refresh is cache.
- Cookie has been removed => this suppose that the backend does not need a cookie to work, that might not be the case for everyone - but if you want to use the cache, it will likely be the case.
- We add a new header ‘X-Forwarded-Host’ with the original hostname.
This kind of small optimisations leverages Cloudflare CDN by removing some variants of the same page and limit the number of hits to the origin server.
Example 2: Workers as response rewriter
Let’s say the backend send a html content with something like this:
<!— other contents —>
<div class=“target-connected”>Content for connected user</div>
<div class=“target-nonconnected”>Content for non-connected user</div>
The response can be cached as it in the Cloudflare CDN, however, the worker will clean the HTML depends if the user is connected or not.
This can be done using HTMLRewriter:
The html send can be either:
<!— other content —>
<div class=“target-connected”>Content for connected user</div>
Or
<!— other content —>
<div class=“target-nonconnected”>Content for non-connected user</div>
Example 3: Workers with KV as a fallback
The Workers can be used with the KV store to return a response if the backend is down. The workflow is simple as: Read the ‘cf-cache-status’ value, if it is MISS or EXPIRED, then store the value in the KV If the backend response is 500 or 502, check if the cached version exists in the KV store, if so return it to the user.
For all others, cases just return the response.
That is for now! More practical (with code) articles will follow.